


Google DeepMind ha presentato poche ore fa Gemini 2.5 Computer Use, un modello specializzato di intelligenza artificiale che cambia ancora l’interazione tra AI e interfacce utente.
La nuova tecnologia, costruita sulle capacità di comprensione visiva e ragionamento di Gemini 2.5 Pro, è già disponibile in anteprima per gli sviluppatori attraverso l’API Gemini su Google AI Studio e Vertex AI.
Come cambia l’interazione con il digitale
Per comprendere cosa cambia con Gemini 2.5 Computer Use, si può iniziare con il ricordare che i modelli di intelligenza artificiale tradizionali si interfacciano con i software attraverso API strutturate. Tuttavia, molte attività digitali richiedono ancora un’interazione diretta con le interfacce grafiche. Compilare moduli, utilizzare menu a tendina, applicare filtri o navigare dietro schermate di login sono infatti operazioni che fino ad oggi hanno richiesto l’intervento umano.
Ebbene, Gemini 2.5 Computer Use vuole cambiare questo ambito, consentendo agli agenti AI di navigare in pagine web e applicazioni esattamente come farebbe una persona: cliccando, digitando e scorrendo.
La capacità del modello di manipolare nativamente elementi interattivi e operare in ambienti protetti da autenticazione è evidentemente un passo molto importante verso la creazione di agenti generici ancora più potenti e versatili di quelli che stiamo vedendo oggi, e Google evidentemente non vuole perdere terreno in questo lato dell’automazione digitale.
Segui Google Italia su Telegram, ricevi news e offerte per primo
Come funziona Gemini 2.5 Computer Use
Il funzionamento di Gemini 2.5 Computer Use si basa su un ciclo iterativo innovativo, con capacità esposte con un nuovo tool chiamato computer_use nell’API Gemini, progettato per operare in un loop continuo.
In pratica, si parte con l’elaborazione degli input forniti al sistema, che includono la richiesta dell’utente, uno screenshot dell’ambiente di lavoro e una cronologia delle azioni recenti. È inoltre possibile specificare quali funzioni escludere dall’elenco completo delle azioni supportate o quali funzioni personalizzate aggiungere.
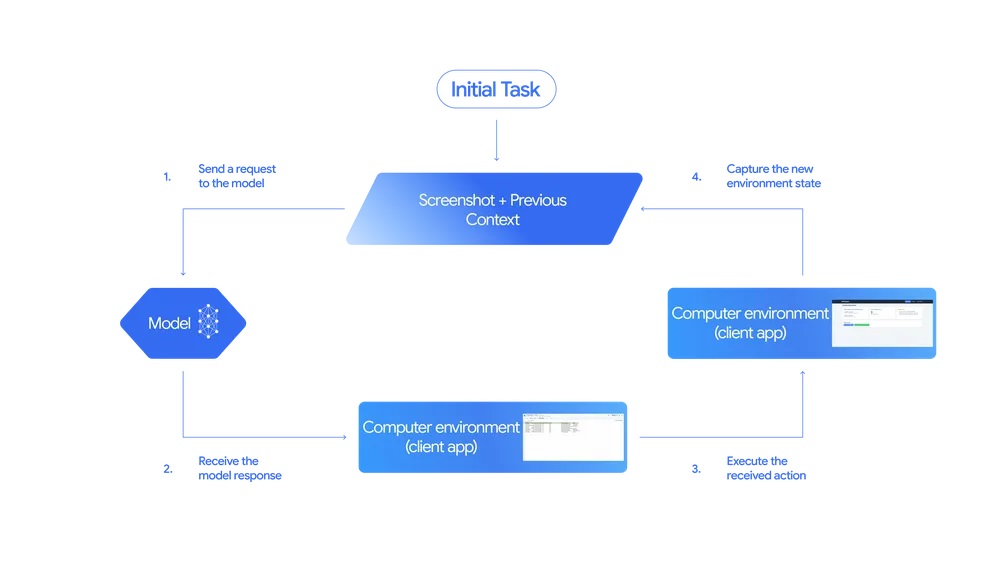

A questo punto, il modello analizza gli elementi forniti e genera una risposta, che è tipicamente una chiamata di funzione che rappresenta un’azione dell’interfaccia utente come un clic o una digitazione di tasti. In alcuni casi, la risposta può contenere una richiesta di conferma da parte dell’utente finale, necessaria per determinate azioni sensibili come un acquisto. Il codice lato client esegue quindi l’azione ricevuta.
Dopo l’esecuzione, un nuovo screenshot dell’interfaccia grafica e l’URL corrente vengono inviati nuovamente al modello Computer Use come risposta della funzione, riavviando un ciclo che continua fino al completamento dell’attività, al verificarsi di un errore o alla terminazione dell’interazione tramite una risposta di sicurezza o decisione dell’utente.
Il modello è ottimizzato soprattutto per i browser web, ma sembra mostrare risultati promettenti anche per le attività di controllo delle interfacce mobili. Al momento non è invece ottimizzato per il controllo a livello di sistema operativo desktop.
Cosa ci dice Google
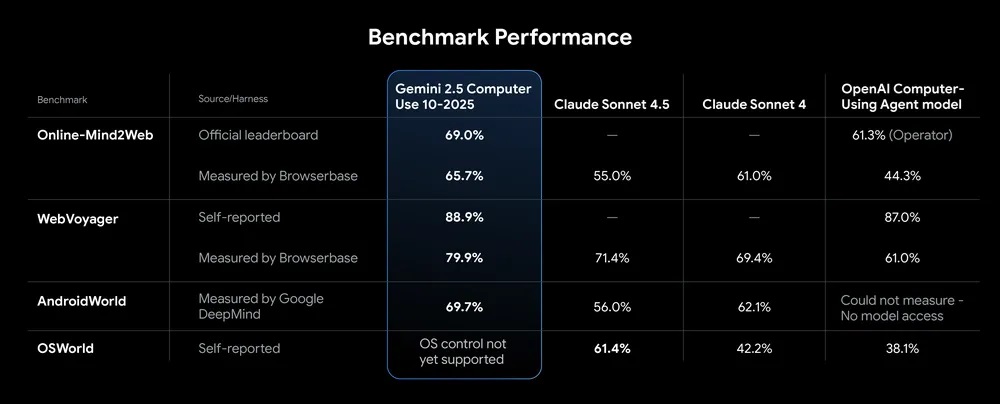
Google ha presentato Gemini 2.5 Computer Use con particolare soddisfazione, sottolineando come stia dimostrando prestazioni eccellenti su diversi benchmark di controllo web e mobile. I risultati ottenuti, ad esempio, riescono ad annoverare valutazioni auto-riportate, test eseguiti da browser e valutazioni condotte direttamente da Google. In tutti i casi, il modello ha superato le principali alternative in molti parametri di riferimento, mantenendo anche una latenza inferiore rispetto alla concorrenza.

Google ha poi richiamato il fatto che costruire agenti in grado di offrire i vantaggi di cui sopra richiede un approccio responsabile fin dall’inizio. Gli agenti AI che controllano computer introducono nuovi rischi, tra cui l’uso improprio intenzionale da parte degli utenti, i comportamenti imprevisti del modello e l’inserimento di prompt o truffe nell’ambiente web. Per questo motivo, è fondamentale implementare con attenzione le protezioni di sicurezza.
Per questo motivo Google informa che il proprio team ha integrato caratteristiche di sicurezza direttamente nel modello per affrontare tre rischi chiave, descritti nella System Card di Gemini 2.5 Computer Use. Inoltre, vengono forniti agli sviluppatori controlli di sicurezza che consentono di impedire al modello di completare automaticamente azioni potenzialmente rischiose o dannose, come il danneggiamento dell’integrità di un sistema, la compromissione della sicurezza, l’aggiramento di CAPTCHA o il controllo di dispositivi medici.
In particolare, i controlli che Google ha implementato includono un servizio di sicurezza per step che valuta ogni azione proposta dal modello prima della sua esecuzione, e istruzioni di sistema che permettono agli sviluppatori di specificare che l’agente debba rifiutare o richiedere conferma all’utente prima di intraprendere specifici tipi di azioni ad alto rischio. Sono inoltre stati diffusi dei documenti che riportano raccomandazioni aggiuntive per gli sviluppatori su misure di sicurezza e best practice, con l’invito a testare accuratamente i sistemi prima del lancio.
Le applicazioni reali della nuova tecnologia
Google informa inoltre di avere già implementato il modello in produzione per casi d’uso come il testing delle interfacce utente, che può rendere lo sviluppo software molto più veloce.
Gli utenti che hanno avuto l’opportunità di entrare nel programma di accesso anticipato hanno testato il modello per alimentare assistenti personali, automazione dei flussi di lavoro e testing delle interfacce, ottenendo risultati che la società di Mountain View definisce soddisfacenti.
Poke.com, un assistente AI per iMessage, WhatsApp e SMS, ha ad esempio dichiarato che Gemini 2.5 Computer Use è ben superiore alla concorrenza, risultando più veloce del 50% rispetto alle migliori soluzioni alternative considerate. Un dato sicuramente non sottovalutabile, considerato che la velocità è un fattore particolarmente importante per i workflow che richiedono interazioni con interfacce pensate per esseri umani.
Autotab, un agente AI drop-in, ha invece riportato che i loro agenti operano in completa autonomia, svolgendo lavori dove piccoli errori nella raccolta e analisi dei dati sono inaccettabili. Anche in questo caso Gemini 2.5 Computer Use sembra aver superato altri modelli nell’analisi affidabile del contesto in casi complessi, aumentando le prestazioni fino al 18% nelle loro valutazioni più difficili.
Come iniziare a utilizzare il modello
A partire da oggi, il modello è disponibile in anteprima pubblica, accessibile tramite l’API Gemini su Google AI Studio e Vertex AI. Gli sviluppatori interessati possono pertanto provarlo immediatamente in un ambiente demo ospitato da Browserbase, oppure iniziare a costruire consultando la documentazione di riferimento per imparare come creare il proprio ciclo agente localmente con Playwright o in una VM cloud con Browserbase.
Google invita con l’occasione la comunità degli sviluppatori a condividere feedback e contribuire alla roadmap del prodotto attraverso il Developer Forum dedicato.

