Dopo l’annuncio ufficiale della scorsa settimana, Google ha iniziato a rendere disponibile a un numero sempre maggiore di utenti una delle funzionalità più interessanti e richieste di Gemini, ovvero la modifica nativa delle immagini, che ora risulta accessibile in modo più semplice e intuitivo rispetto al passato.
Una novità che segna un ulteriore passo avanti verso un utilizzo creativo e produttivo dell’IA generativa da parte degli utenti comuni, anche al di fuori del contesto sperimentale.

Gemini migliora ancora, la modifica nativa delle immagini è maggiormente disponibile
Finora, quando si chiedeva a Gemini di modificare un’immagine precedentemente generata o fornita dall’utente, il comportamento predefinito del chatbot era quello di ricreare un contenuto del tutto nuovo, spesso e volentieri con soggetti, sfondi e colori completamente diversi rispetto all’immagine originale.
Ora invece l’approccio è radicalmente diverso, grazie all’editing nativo Gemini riesce a conservare la struttura originale dell’immagine e ad apportare solo le modifiche richieste dall’utente sfruttando semplici prompt in linguaggio naturale. Il risultato è un’esperienza molto più simile a quella di un editor di immagini classico, ma con tutta la flessibilità dell’intelligenza artificiale.
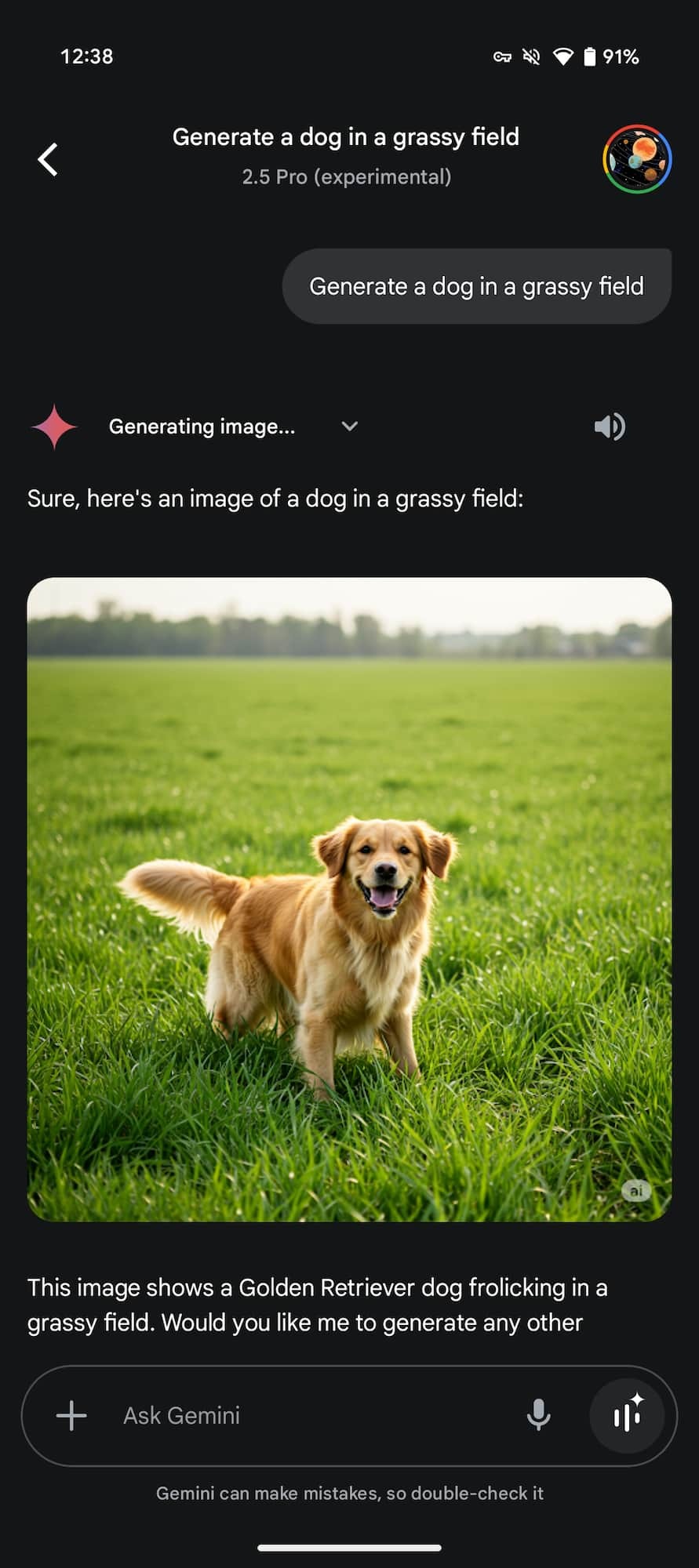
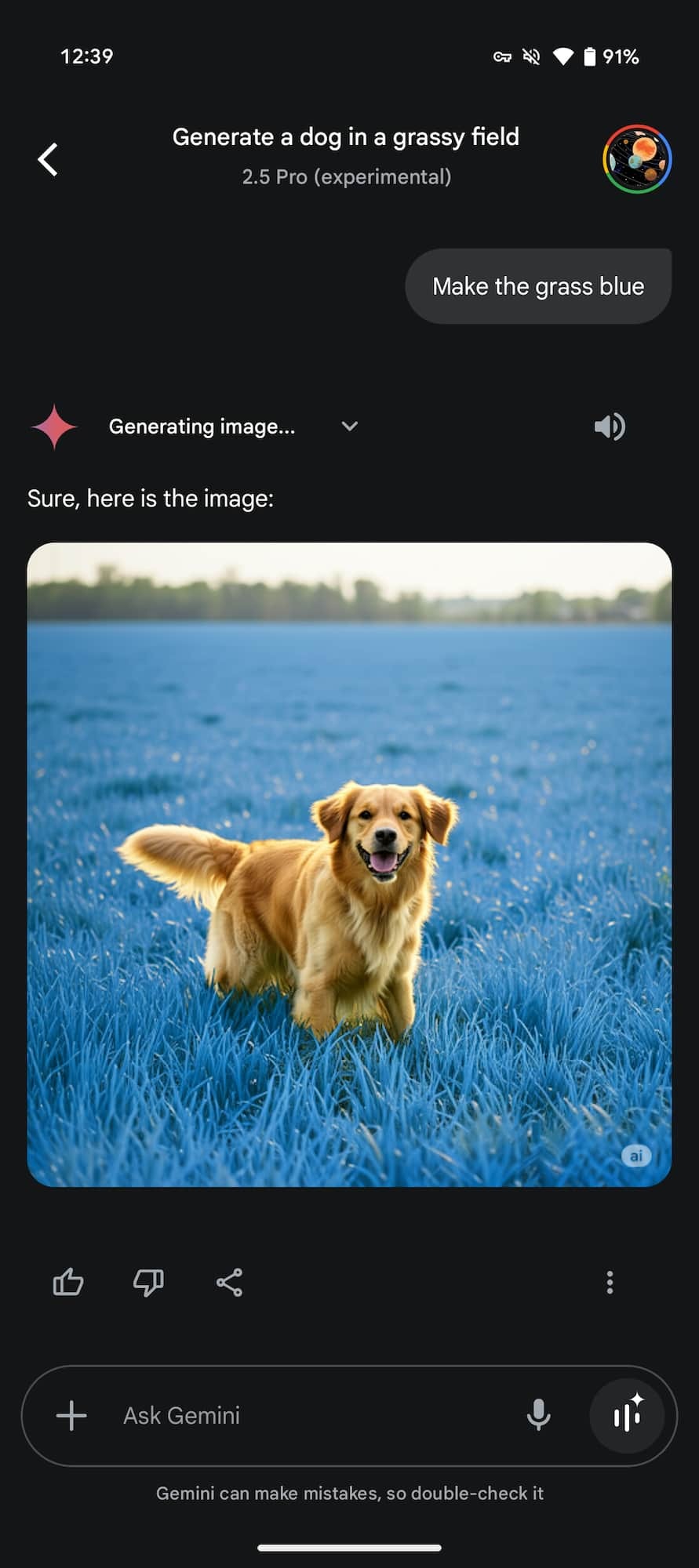
La nuova modalità di editing funziona sia sulle immagini generate direttamente da Gemini che su quelle caricate manualmente dall’utente, è sufficiente una richiesta testuale e il sistema si occuperà di applicare il cambiamento in modo preciso, senza alterare gli elementi non coinvolti nella modifica.
Nelle immagini poco sopra potete infatti notare come sia ora possibile ottenere un cambiamento mirato, l’IA di Google ha mantenuto il soggetto, gli alberi sullo sfondo e il cielo, modificando esclusivamente il colore dell’erba come richiesto; si tratta di un enorme passo avanti rispetto al comportamento precedente dello strumento.
Tra le novità più interessanti c’è anche l’introduzione di una nuova filigrana visiva con l’etichetta “ai”, posizionata nell’angolo in basso a destra delle immagini generate, una scelta che si aggiunge alla già esistente filigrana digitale invisibile SynthID e che punta a migliorare la tracciabilità e la trasparenza nell’utilizzo dei contenuti creati dall’IA.
Ma non è tutto, l’editing visivo ora si integra perfettamente nella conversazione, permettendo modifiche multi-step e risposte con testo e immagini combinate; ciò apre scenari molto interessanti come tutorial visuali passo passo, bozze grafiche per storie illustrate o addirittura simulazioni personalizzate (per esempio è possibile caricare una propria foto e vedere come si apparirebbe con un colore di capelli diverso).
Dal punto di vista tecnico il sistema sfrutta le capacità del modello Gemini 2.0 Flash recentemente lanciato, ma le funzionalità di editing sono accessibili da qualsiasi modello, quindi non è necessario essere legati ad una specifica versione per poterne usufruire.
In parallelo, Google ha annunciato la disponibilità in anteprima delle API per la generazione e modifica immagini tramite Google AI Studio e Vertex AI, dedicate agli sviluppatori; rispetto ai test condotti in precedenza vengono promessi miglioramenti sostanziali nella qualità visiva, nella fedeltà del rendering testuale e nella riduzione dei tempi di blocco legati ai filtri di sicurezza.
Al momento, la nuova funzione di editing nativo sembra essere ampiamente disponibile negli Stati Uniti, su account gratuiti e a pagamento; non ci sono ancora conferme ufficiali sulla disponibilità globale ma, considerando la natura server side della funzione e la rapida evoluzione dei servizi Gemini, è lecito aspettarsi un’estensione anche ad altri Paesi (Italia inclusa) nel corso delle prossime settimane.
- Un’indiscrezione svela le “Gemini Actions” su Wear OS: ecco come funzioneranno
- Google proverà a rendere Gemini Live l’assistente perfetto con il supporto alle App
- Google svela Gemini 2.5 Pro con potenziate capacità di coding e sviluppo web
- Gemini è ora in grado di analizzare più immagini in contemporanea