
Il panorama dell’intelligenza artificiale generativa si fa sempre più affollato e competitivo, ma Xiaomi non sembra affatto intimorita. Anzi, l’azienda cinese ha deciso di gettare il guanto di sfida presentando MiMo, un nuovo modello linguistico di grandi dimensioni (LLM) che promette di distinguersi per una caratteristica ben precisa: le capacità di ragionamento.
Una mossa ambiziosa, orchestrata da un team interno di nuova costituzione, lo “Xiaomi Big Model Core Team”, che segna l’ingresso ufficiale del colosso tecnologico nell’arena dell’AI open-source con un progetto decisamente interessante.
Indice:
Segui Xiaomi Italia su Telegram, ricevi news e offerte per primo

MiMo è un “piccolo” modello con grandi ambizioni
A prima vista, MiMo potrebbe non sembrare rivoluzionario per le sue dimensioni. Si tratta di un modello da 7 miliardi di parametri, una taglia considerevole ma non paragonabile ai veri e propri titani del settore che vantano decine o centinaia di miliardi di parametri.
Tuttavia, è proprio qui che risiede la peculiarità della proposta di Xiaomi. L’azienda afferma, infatti, che MiMo sia in grado di competere ad armi pari, se non superare, modelli significativamente più grandi, specialmente quando si tratta di compiti che richiedono un elevato grado di ragionamento logico-matematico e nella generazione di codice di programmazione. Nomi altisonanti come o1-mini di OpenAI e persino un’anteprima del modello Qwen da 32 miliardi di parametri di Alibaba vengono citati come termini di paragone.
Ottenere prestazioni di ragionamento così elevate da un modello relativamente compatto non è affatto semplice. Xiaomi stessa riconosce che i risultati più impressionanti, soprattutto quelli derivanti da tecniche di apprendimento per rinforzo (Reinforcement Learning – RL), solitamente provengono da architetture molto più vaste. Qual è dunque l’“asso nella manica” di Xiaomi? Sembra risiedere nella capacità di massimizzare il potenziale intrinseco del modello base da 7 miliardi di parametri.
Questo sarebbe stato possibile grazie a strategie mirate e ottimizzate implementate sia durante la fase di pre-addestramento (pre-training) sia in quella successiva di affinamento (post-training). Un vantaggio collaterale non trascurabile di un modello più snello è la sua potenziale maggiore usabilità: potrebbe essere adottato più facilmente da aziende che non dispongono di enormi cluster GPU o, in futuro, potrebbe persino essere eseguito su dispositivi “edge” con risorse limitate, come smartphone o altri gadget.
Sotto il cofano: come è stato costruito MiMo?
Ma come hanno fatto gli ingegneri Xiaomi a infondere queste capacità di ragionamento nel loro modello? L’approccio è tecnico, ma cerchiamo di scomporlo in più parti.
Fase 1: affinare le basi con il Pre-Training
Il fondamento di MiMo risiede in un processo di pre-addestramento profondamente ottimizzato. Xiaomi sottolinea di aver lavorato intensamente sulla gestione dei dati: migliorando l’elaborazione dei dati grezzi, potenziando gli strumenti per estrarre testo rilevante e applicando molteplici livelli di filtraggio. L’obiettivo dichiarato era aumentare la densità dei pattern di ragionamento all’interno del materiale di addestramento. Non si è trattato, quindi, di “dare in pasto” dati alla rinfusa, ma di curare attentamente il materiale didattico del modello.
È stato creato un dataset specializzato contenente circa 200 miliardi di “token” di ragionamento (i token sono le unità base del linguaggio per un AI, come pezzi di parole o codice). Successivamente, è stata applicata una strategia di “data mixing” a tre stadi, addestrando progressivamente il modello su un volume impressionante di 25 trilioni di token totali. Un carico di apprendimento davvero massiccio. Inoltre, è stata impiegata una tecnica chiamata Multiple-Token Prediction (MTP), che, secondo Xiaomi, non solo ha migliorato le prestazioni del modello, ma contribuisce anche a velocizzare la generazione delle risposte in fase di utilizzo.
Fase 2: perfezionare le abilità con il Reinforcement Learning
Dopo la costruzione iniziale, si è passati alla fase di messa a punto fine tramite apprendimento per rinforzo (RL). A MiMo sono stati sottoposti circa 130.000 problemi di matematica e programmazione. Un dettaglio cruciale è che questi problemi sono stati verificati per accuratezza e difficoltà utilizzando sistemi basati su regole, nel tentativo di garantire che il modello imparasse da esempi validi e corretti.
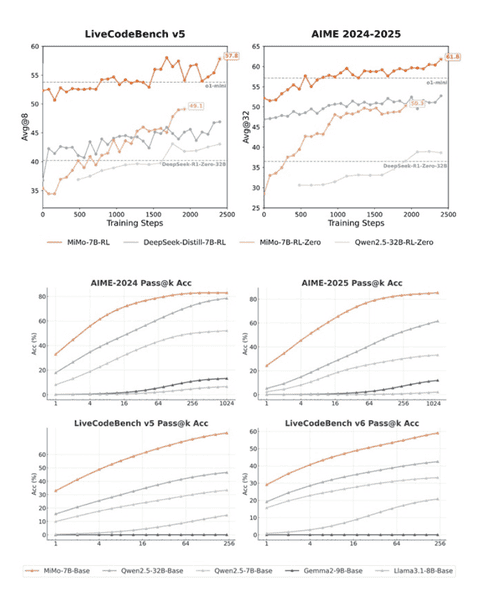
Il Reinforcement Learning, tuttavia, può presentare delle sfide con problemi complessi dove le risposte corrette (e quindi le “ricompense” per l’AI) sono rare (un fenomeno noto come “sparse rewards” o ricompense sparse). Per aggirare questo ostacolo, il team Xiaomi ha implementato due strategie intelligenti. La prima è un sistema chiamato “Test Difficulty Driven Reward”, che presumibilmente adatta la ricompensa in base alla difficoltà del problema affrontato. La seconda è l'”Easy Data Re-Sampling“, una tecnica che sembra mirare a mantenere stabile l’addestramento RL rivisitando efficacemente i problemi più semplici.
Accelerare lo sviluppo: l’importanza dell’efficienza
Addestrare questi modelli richiede tempi lunghissimi e una potenza computazionale enorme. Per ottimizzare questo processo, Xiaomi ha sviluppato internamente uno strumento chiamato “Seamless Rollout Engine”. Lo scopo è ridurre i tempi morti delle GPU durante i cicli di addestramento e validazione.
I risultati dichiarati sono notevoli: un’accelerazione del 2.29x nell’addestramento e del 1.96x nella validazione. Ottimizzare i tempi è fondamentale nello sviluppo dell’AI. Questo engine, inoltre, supporta la tecnica Multiple-Token Prediction all’interno del popolare framework vLLM e, in generale, rende più stabile l’inferenza del sistema RL di Xiaomi.
Una famiglia di modelli: le varianti di MiMo
Xiaomi non ha rilasciato una singola versione, ma un’intera famiglia MiMo-7B, composta da quattro varianti:
- MiMo-7B-Base: Il modello fondamentale, punto di partenza con un forte potenziale di ragionamento dichiarato.
- MiMo-7B-RL-Zero: Un modello addestrato con RL partendo direttamente dalla versione Base.
- MiMo-7B-SFT: Una versione creata tramite Supervised Fine-Tuning (addestramento supervisionato mostrando esempi corretti).
- MiMo-7B-RL: Sembra essere la versione più performante. È un modello RL addestrato partendo dalla versione SFT ed è quello che Xiaomi ha utilizzato per i benchmark comparativi con altri modelli come o1-mini di OpenAI.
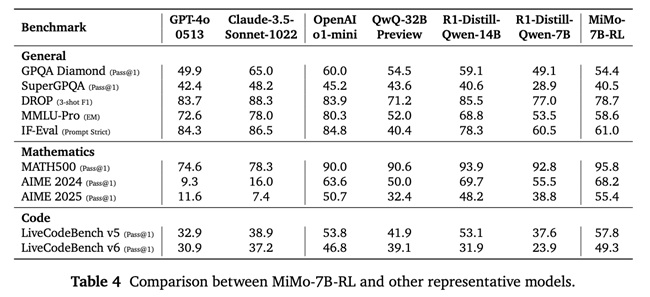
Alla prova dei fatti: i risultati dei benchmark
Xiaomi ha condiviso una serie di punteggi ottenuti dalla variante MiMo-7B-RL (testata con un’impostazione specifica, temperatura = 0.6). I benchmark sono solo una parte del quadro complessivo, ma forniscono un’indicazione interessante sulle capacità del modello:
- Matematica:
- MATH-500: Raggiunge il 95.8% di accuratezza al primo tentativo (Pass@1) in una singola esecuzione. Un risultato decisamente solido.
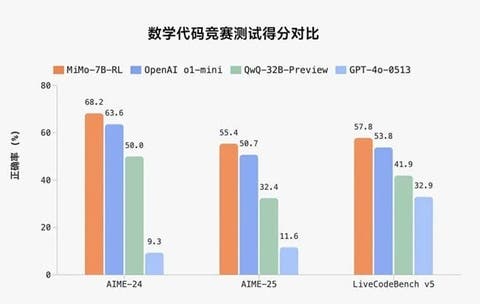
- AIME 2024 (una competizione matematica impegnativa): Media del 68.2% Pass@1 su 32 esecuzioni.
- AIME 2025: Media del 55.4% Pass@1 su 32 esecuzioni.
- Generazione di Codice:
- LiveCodeBench v5: 57.8% Pass@1 (media su 8 esecuzioni).
- LiveCodeBench v6: 49.3% Pass@1 (media su 8 esecuzioni). Punteggi che appaiono competitivi.
- Ragionamento Generale / Compiti Vari:
- GPQA Diamond: 54.4% Pass@1 (media su 8 esecuzioni).
- SuperGPQA: 40.5% Pass@1 (singola esecuzione).
- DROP (Comprensione del testo, punteggio F1): 78.7.
- MMLU-Pro (Conoscenza ampia, Corrispondenza Esatta): 58.6.
- IF-Eval (Seguire istruzioni): 61.0 (media su 8 esecuzioni).
Analizzando questi numeri, specialmente i risultati in matematica, MiMo sembra effettivamente molto capace per le sue dimensioni. Anche le prestazioni nella programmazione e nei compiti generali appaiono competitive nel panorama attuale.
Dove trovare e come usare MiMo: l’importanza dell’Open Source
Forse la notizia migliore per sviluppatori e ricercatori è l’accessibilità. Xiaomi ha reso l’intera serie di modelli MiMo-7B open-source. I modelli sono disponibili per il download e l’utilizzo sulla piattaforma Hugging Face (a questo indirizzo). Per chi volesse approfondire gli aspetti tecnici, l’azienda ha pubblicato anche un report completo e i checkpoint del modello su GitHub.
È senza dubbio positivo vedere un altro grande nome della tecnologia contribuire attivamente alla comunità open-source con strumenti potenzialmente potenti. Ora non resta che attendere e vedere come la comunità di sviluppatori e le aziende inizieranno a sfruttare MiMo nel mondo reale. Le premesse sono certamente intriganti.
- Stretta sugli acceleratori IA: il chip H20 di NVIDIA bloccato dagli USA
- ChatGPT si potenzia: arrivano shopping, ricerca via WhatsApp e fonti più affidabili
- WADAS è un nuovo sistema intelligente per la salvaguardia degli animali selvatici
- Amazon Nova Sonic sembra essere l’ingrediente giusto per far diventare grande Alexa