
Lo scorso ottobre Google ha reso disponibile a tutti gli sviluppatori Cloud Text-to-Speech con le realistiche voci WaveNet di DeepMind. Gli aggiornamenti a Cloud TTS e a Speech-to-Text aggiungono nuove lingue e voci e prezzi più convenienti.
Il riconoscimento vocale Speech-to-Text è importante per applicazioni e dispositivi vocali e utile anche per la trascrizione di video e nelle impostazioni del call center.
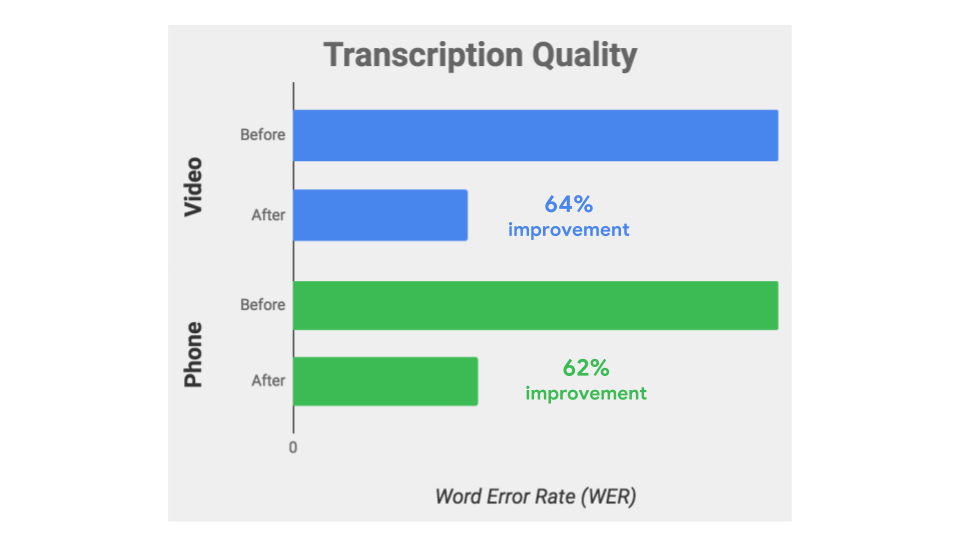
L’anno scorso Google ha chiesto agli utenti di condividere i dati sull’utilizzo della piattaforma per migliorare l’accuratezza di questi modelli premium e oggi il colosso di Mountain View si dichiara entusiasta che il modello telefonico ora ha il 62% di errori di trascrizione in meno, mentre il modello video, che si basa su una tecnologia simile a quella utilizzata da YouTube per i sottotitoli automatici, ha ora il 64% di errori in meno.

Il modello telefonico migliorato è ora ampiamente disponibile senza registrazione dei dati, ma sarà più costoso. Le opzioni esistenti con la condivisione dei dati abilitata a migliorare la precisione sono ora del 33% più economiche, mentre il modello video sta inserendo la disponibilità generale (GA) con SLA e garanzie a livello aziendale, oltre al riconoscimento multicanale per le situazioni con più di un oratore.
Cloud Text-to-Speech è ora disponibile in versione beta per sette nuove lingue/varianti: danese, portoghese/portogallo, russo, polacco, slovacco, ucraino e norvegese Bokmål, portando a 21 il totale delle lingue per Cloud TTS, con 31 nuove voci WaveNet e 24 nuove voci standard annunciate oggi per un totale di 106 voci in tutto.