
Ne avevamo parlato già a inizio primavera del Cloud Text-to-Speech, il servizio di Google per le sintesi vocali realizzato in collaborazione con la compagnia specializzata nell’AI, DeepMind, e della sua tecnologia nota come WaveNet.
A distanza di vari mesi da quel primo approccio in cui ve ne parlavamo ora la soluzione di Big G è disponibile per tutti gli sviluppatori di app di terze parti arricchita peraltro di nuove funzionalità e soprattutto di nuove lingue e voci WaveNet.
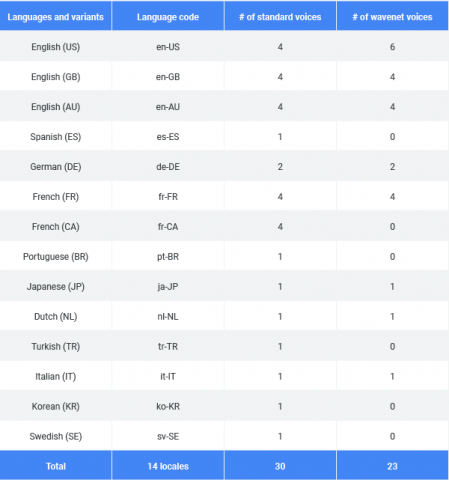
Queste ultime sono in diciassette ed entrano a far parte del bagaglio vocale del sistema che ora conta in totale 30 voci standard e 23 varianti WaveNet per 14 lingue, italiano compreso.
Ci sono poi altre novità nella beta che riguardano ad esempio la possibilità di ottimizzare la resa specificando il dispositivo correlato su cui viene progettato il profilo audio e aggiornamenti vari alle API di Cloud Speech-to-Text.
Si parla poi di riconoscimento multicanale per la separazione fra canali audio come pure del rilevamento automatico della lingua e di una funzionalità in più che permetterebbe al sistema di chiedere all’utente maggior chiarezza su un punto specifico di una frase da trascrivere anziché invitare quest’ultimo a ripetere tutto per intero.
Insomma, Google procede nei lavori e la questione pare diventare sempre più interessante non credete? Il box dei commenti sottostante è come sempre a vostra disposizione.