
L’ASUS Transformer Prime è solo il primo dei dispositivi Android che avranno al loro interno un processore quad core – ed in questo caso sarà l’evoluzione del processore dual core nVIDIA Tegra 2 a fornire la potenza di calcolo necessaria al tablet. Precedentemente noto come “Progetto Kal-El”, il nuovo processore progettato e prodotto da nVIDIA si chiama ufficialmente Tegra 3.
Nel 2011 nVIDIA è riuscita ad imporsi nettamente sulla concorrenza con il suo processore Tegra 2, tanto da arrivare quasi ad un monopolio nei tablet e negli smartphone di fascia alta ed altissima: è per questo che il 2011 è stato denominato dalla testata specialistica SlashGear “l’anno di nVIDIA”.
Ma quali sono le novità contenute in questa nuova generazione di processori? Vediamolo insieme.
Un po’ di storia
Ciò che molti si chiedono è: perché utilizzare più processori in parallelo invece che uno solo molto potente? Nel 2001 l’azienda americana Intel, leader nella produzione di processori con circa il 90% di quota di mercato, lanciò la prima generazione di processori Pentium 4 e – quasi in contemporanea – vennero annunciati i processori Pentium 3 “Tualatin”, evoluzione dei Pentium 3. Intel, sotto pressione del reparto marketing e senza tenere conto dei limiti fisici del silicio, pensava di poter aumentare la frequenza di clock a dismisura senza incontrare particolari problemi: per questo motivo pensò di allungare a dismisura la pipeline, ovvero la serie di stadi interni al processore che servono per decodificare ed eseguire le istruzioni dei programmi presenti in memoria. Solitamente una pipeline lunga è meno prestante di una corta, ma una pipeline molto lunga (più di 30 stadi!) è completamente inefficiente se impiegata con frequenze di clock basse. I primi Pentium 4, chiamati “Willamette”, erano meno efficienti e meno prestanti a parità di velocità di clock con i Pentium 3 “Tualatin” rilasciati quasi in contemporanea. Intel tuttavia aveva speso molto nella ricerca per i Pentium 4 e quindi spinse molto sul marketing dei nuovi processori nonostante i noti problemi di inefficienza e di scarse prestazioni, puntando moltissimo sulla ignoranza delle persone comuni che, senza avere conoscenze sufficientemente approfondite, ritenevano (a torto) che una maggiore frequenza di clock portasse a prestazioni sicuramente migliori. Ciò non era ovviamente vero, poiché AMD produceva processori con una architettura migliore rispetto ad Intel che riuscivano ad esprimere prestazioni migliori rispetto ai processori dell’avversaria – ma la macchina del marketing ormai aveva segnato un’era di successo per Intel. La stessa azienda di Santa Clara aveva azzardatamente annunciato – principalmente per motivi di marketing – sviluppi per il futuro che avrebbero portato i processori a velocità di clock tra i 7 e i 10 GHz: purtroppo i limiti fisici del silicio (maggiore la velocità di clock, maggiore la corrente necessaria e maggiore il calore prodotto da dissipare) segnarono uno dei più grandi fallimenti nella storia di questa azienda, che commercializzò la versione più veloce del suo Pentium 4 fermandosi a “soli” 3,8GHz.
È a questo punto che entrò in scena AMD proponendo processori con una frequenza di clock minore rispetto al passato, ma con più unità di elaborazione (detta “core” in inglese). Il concetto era semplice: se non posso aumentare la potenza di un singolo motore, allora impiego più motori. Si aprì l’era dei processori multicore.
Quattro è meglio di due
L’aumento del numero di core all’interno dei processori porta a due considerazioni: la prima è che più core sono presenti e maggiore è la potenza di elaborazione disponibile; la seconda è che non sempre ad un incremento dei core corrisponde un incremento nelle prestazioni dei programmi.
La prima considerazione è facilmente spiegata: se utilizzo due motori uguali sulla macchina avrò indubbiamente più potenza a disposizione rispetto ad usarne uno, e se ne utilizzo 4 avrò molta più potenza rispetto a quando ne utilizzo 2. Tuttavia, come recita un noto spot pubblicitario, “la potenza è nulla senza controllo”.
Il controllo, in questo caso, è rappresentato dalla scrittura del codice: i programmatori, per usufruire appieno della potenza delle CPU multicore, devono scrivere il proprio codice “parallelizzandolo” ovvero pensandolo per essere eseguito su più unità di elaborazione che eseguono contemporaneamente parti diverse del programma. In questo modo è possibile distribuire il carico tra i core, mentre ciò non è possibile se il codice è stato scritto per utilizzare un solo processore per volta.
Anche se il codice non è stato parallelizzato, tuttavia, la possibilità di sfruttare i core si concretizza nel multitasking: è molto più semplice tenere aperte 4 applicazioni quando ciascuna ha un processore a sua disposizione, piuttosto che tenere aperte 4 applicazioni che devono utilizzare un singolo processore e “spartirselo” tra di loro. Se quindi “ciù is megl che uan”, citando ancora una volta un noto spot pubblicitario, allora è vero anche che “quatr is megl che ciù”!
I concetti sono volutamente semplificati, poiché non è questa la sede di una discussione approfondita riguardo la progettazione dei processori e delle applicazioni software.
L’architettura di Tegra 3: principi generali
Come il predecessore Tegra 2, Kal-El fa utilizzo dell’architettura ARM Cortex-A9 utilizzando 4 core con frequenze di clock che variano tra 1GHz e 1,5GHz. Le prestazioni del singolo core non differiscono dunque sostanzialmente da quanto Tegra 2 era in grado di esprimere, tuttavia la presenza di due core aggiuntivi aumenta notevolmente le prestazioni in applicazioni che sfruttano tutti i core. Sorprendente è che il rapporto prestazioni per watt è decisamente maggiore rispetto alla generazione precedente e ai processori single core, nonostante l’aumento di unità di processazione all’interno: questo perchè la distribuzione del carico tra le varie componenti utilizzate parzialmente permette di portare a termine il lavoro più in fretta e con meno consumi rispetto all’utilizzo intensivo e la concentrazione del carico su una sola componente utilizzata pienamente. La possibilità di “spegnere” i core nel momento in cui non ci sia bisogno di potenza di elaborazione od “accenderli” quando vengono eseguite applicazioni che richiedono maggiore potenza incrementa il risparmio energetico. Ciò significa che la batteria durerà di più e sarà gestita più efficacemente rispetto ai processori dell’attuale generazione.
L’architettura di Tegra 3: il “companion core”

La grande innovazione presentata da nVIDIA con l’ultima generazione di processori mobile consiste nell’adozione, accanto ai quattro core tradizionali, di un quinto core con frequenza di clock minore, chiamato “companion core”. Questo quinto core è prodotto utilizzando un particolare processo produttivo che riduce i consumi, ed è stato inserito appositamente per entrare in funzione quando c’è necessità di poca potenza elaborativa e grandi capacità di risparmio energetico. Lo scenario di utilizzo di un simile processore è facilmente immaginabile: mentre quattro core molto potenti consumano molto anche quando sono in idle, un solo core depotenziato consuma molto poco quando è inattivo. Moltissimo tempo dei nostri dispositivi è passato in standby, senza un utilizzo apprezzabile della CPU ma con consumi ugualmente elevati a causa dei processi in esecuzione: nVIDIA chiama questo stato “standby attivo”, poiché anche se il dispositivo è in standby continua a utilizzare le risorse.
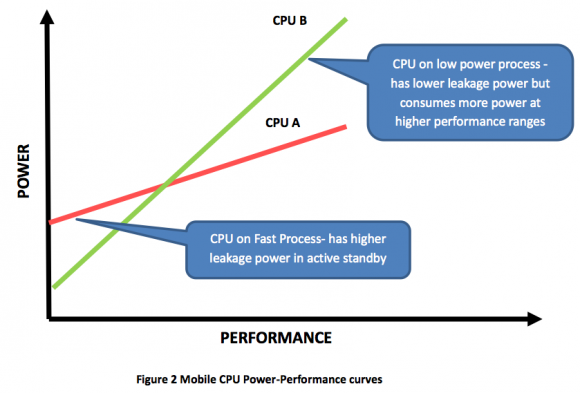
Come è possibile vedere dal grafico sopra riportato, la capacità di consumare meno a bassi livelli di utilizzo del companion core (indicato in verde) è decisamente maggiore di quella offerta dai restanti quattro (indicati in rosso), attivati solo quando i processi attivi richiedono maggiore capacità computazionale. In inglese si parla di “leakage power” (traducibile con “energia di scarto”), ovvero di spreco di energia risultante dalle interazioni fisiche all’interno dei circuiti CMOS (per approfondire: http://www.eetimes.com/electronics-news/4215605/Leakage-power—it-s-worse-than-you-think), e nVIDIA è riuscita ad ottimizzare la produzione del companion core in modo da avere un minore leakage power che garantisce consumi minori in standby e una maggiore durata della batteria.

Il companion core è trasparente al sistema operativo, e ciò significa che il sistema operativo non vede la differenza tra i quattro core principali e quello secondario: non c’è dunque necessità di adattare il software al nuovo hardware per sfruttare le nuove tecnologie offerte.
Un video pubblicato da nVIDIA rende meglio l’idea di come il companion core viene impiegato.
L’architettura di Tegra 3: prestazioni
Rispetto alla attuale generazione di processori dual core, Tegra 3 si pone ad un livello decisamente superiore con prestazioni che arrivano a volte fino al 100% in più. Rispetto ai processori Texas Instruments OMAP4430 e Qualcomm Snapdragon MSM8660, capaci di prestazioni notevoli, nel benchmark CoreMark (che mette i processori sotto sforzo intenso con varie operazioni multimediali) Tegra 3 riesce ad esprimere prestazioni anche doppie, con l’OMAP4430 al secondo posto.
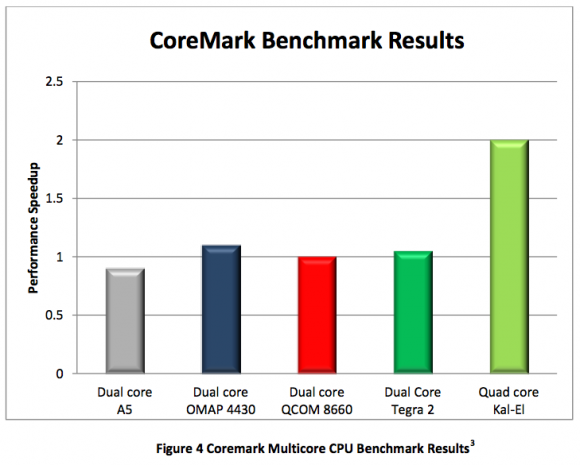
Curiosamente il SoC di Apple, l’A5, ottiene un punteggio leggermente inferiore alle altre proposte dual core e si posiziona ultimo tra le soluzioni prese in considerazione. Un’altra interessante prova svolta da nVIDIA è un confronto dei risultati del benchmark Linpack tra un processore Kal-El dual core ed un processore Kal-El quad core.
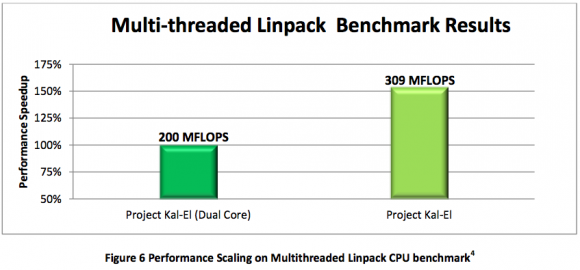
Come è possibile vedere, la proposta quad core distanzia di molto la proposta a soli due core evidenziando ancora una volta la superiorità di quest’ultima tipologia di processore. Sempre proseguendo sulla linea del confronto tra i propri prodotti, nVIDIA mette a confronto le prestazioni ottenute nei giochi da Tegra 2 e da Tegra 3. È lecito aspettarsi, ancora una volta, un dominio della nuova proposta sulla vecchia.
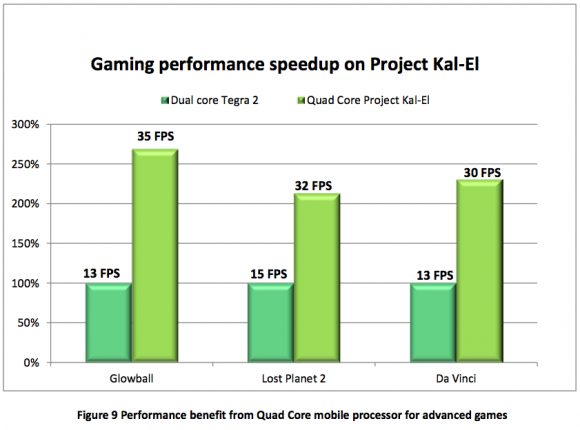
Dominio che è ancora più marcato di quanto visto precedentemente, dato che in Glowball Tegra 3 ottiene quasi 3 volte i fotogrammi di Tegra 2.
Già in occasione della presentazione preliminare del progetto Kal-El nVIDIA aveva mostrato le capacità del processore attraverso il gioco dimostrativo Glowball che fa ampio utilizzo delle luci e delle superfici riflettenti, tipicamente tra gli aspetti più complessi ed esigenti in termini di prestazioni da realizzare. Altro aspetto peculiare del gioco è sia la realizzazione dell’ambiente sia il calcolo della fisica in tempo reale, che aumentano enormemente i requisiti hardware necessari per far funzionare il gioco correttamente e fluidamente.
nVIDIA ha pubblicato anche un secondo video inedito circa il gioco Glowball: la pallina luminosa si muove questa volta sul fondale marino, illuminando la flora e la fauna che si muovono non solo seguendo la direzione della corrente ma anche in caso la pallina li vada ad urtare secondo un modello fisico abbastanza realistico.
Oltre che tramite benchmark, è possibile verificare le prestazioni di Tegra 3 anche attraverso la navigazione web, forse l’attività più comune compiuta con smartphone e tablet. Applicazioni come Flash sono molto più veloci rispetto alle piattaforme concorrenti, così come l’editing di foto e video – e ovviamente anche i giochi hanno prestazioni migliori.
L’architettura di Tegra 3: il variable Symmetric MultiProcessing (vSMP) ed i consumi
La tecnologia SMP consiste nella capacità di far operare simmetricamente i quattro processori e farli accedere alle stesse risorse (cache, memoria, memoria di massa) tramite una sola istanza di un sistema operativo. NVIDIA ha sviluppato e brevettato la tecnologia vSMP: con funzioni del tutto simili alla tecnologia SMP, vSMP aggiunge tuttavia la gestione del companion core e la gestione dei quattro core principali. Come già precedentemente anticipato in “principi generali”, nVIDIA ha progettato Tegra 3 appositamente per consentire il massimo risparmio energetico: attraverso l’utilizzo di una linea di voltaggio per ogni core è possibile spegnere i core non utilizzati, contrariamente ad altri processori dove esiste una sola linea di voltaggio comune a tutti i core, i quali dunque utilizzano grandi quantità di energia se uno solo dei core è attivo e gli altri in idle a causa del fatto che tutti i core ricevono lo stesso voltaggio. nVIDIA ha implementato circuiti e logiche avanzati tali da separare completamente ogni core dagli altri e da permettere lo spegnimento totale di uno o più core in tempi tali da non interferire con le operazioni del sistema operativo e delle applicazioni: si parla di 2 millisecondi per attivare i core e stabilizzare il voltaggio, un tempo decisamente impossibile da essere notato per gli esseri umani.
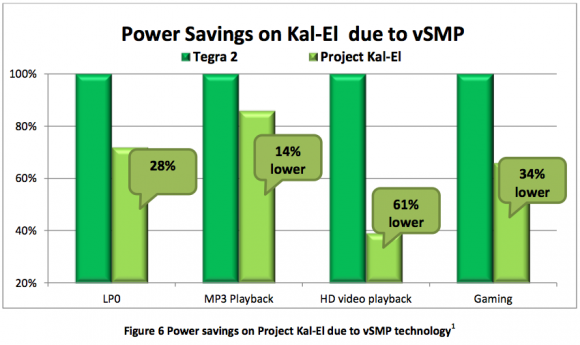
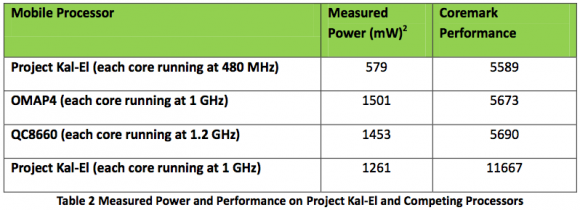
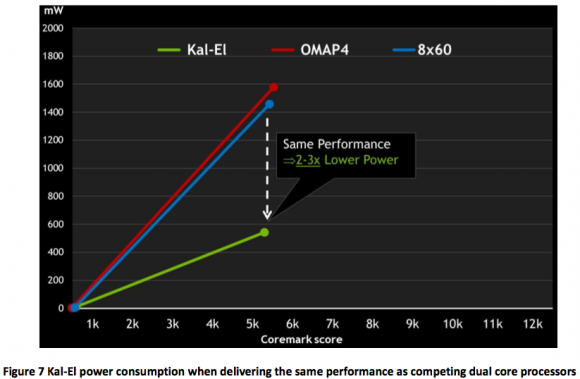
Questa capacità di disattivare o riattivare i core all’occorrenza porta ad un forte risparmio energetico, che va dal 28% in idle al 62% durante la riproduzione di filmati in HD. La minore richiesta energetica rispetto a Tegra 2 per svolgere gli stessi compiti porta anche ad una ulteriore considerazione: se a consumi minori ottengo le stesse prestazioni, a consumi uguali otterrò prestazioni maggiori. Questo è confermato da un ulteriore test svolto da nVIDIA, nel quale viene dimostrato che Tegra 3 è in grado di operare con le stesse prestazioni a 2-3 volte meno energia assorbita rispetto alla concorrenza dual core.
{kind=link}
{kind=link}
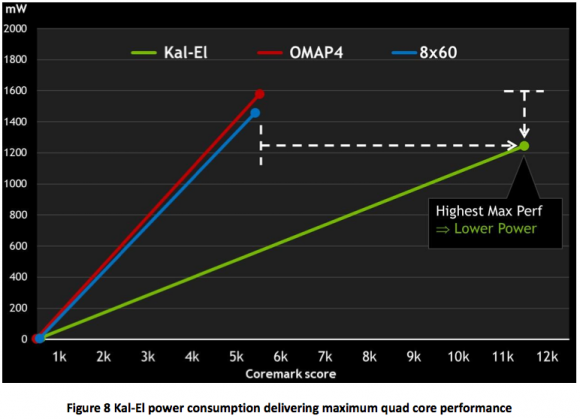
Ciò che ci si aspetta è che, per ottenere le massime prestazioni, Tegra 3 assorba molta più energia di quanta ne assorbano i processori dual core: in realtà, nVIDIA è riuscita ad ottenere prestazioni quasi doppie consumando meno. I grafici qui sotto riportati mostrano che Tegra 3, a piena potenza, consuma meno dei processori OMAP4430 e MSM8660, che ottengono circa 5500 punti nel benchmark, pur esprimendo prestazioni vicine agli 11000 punti.
Software: i giochi
Sin dall’annuncio si parla molto di Tegra 3 come piattaforma in grado di garantire ottime prestazioni nei giochi. Ciò è ancora più vero quando si pensa che giochi come Shadowgun e Riptide GP sono stati ottimizzati per la piattaforma e sono disponibili video di anteprima: confrontando i video a quanto ottenuto con Tegra 2 gli effetti grafici sono più ricchi, sono presenti più dettagli e più effetti fisici.
In Riptide GP sono presenti le gocce degli schizzi d’acqua, un maggiore realismo nella reazione dell’acqua ai corpi fisici ed altri dettagli. In Shadowgun gli oggetti subiscono danni, sono presenti effetti grafici più complessi e le texture sono molto più dettagliate.
Maggiori informazioni
Chi volesse maggiori informazioni può trovarle presso il sito nVIDIA (http://www.nvidia.com/object/IO_90715.html) oppure presso il blog ufficiale (http://blogs.nvidia.com/2011/09/quad-core-kal-el%E2%80%99s-stealth-fifth-core-lets-it-save-on-energy/).
Fonti:
http://www.slashgear.com/nvidia-tegra-2-quad-core-mobile-processor-revealed-and-detailed-09194118/
http://www.slashgear.com/nvidia-expands-on-project-kal-el-adds-a-fifth-core-20181043/